UX CASE STUDY --- Space ManufacturingThe floor couldn’t stop, so neither could I..
How I designed and shipped a mission-critical production floor management system for an aerospace additive manufacturing team in just 10 months, with a three person team, no approved tools, and blockages causing a mid-project pivot. Since the deadline was fixed and engine builds and rocket launches depended on AM parts, there was no room to slip.
My role: UX Designer + PM + Product Owner
Project Context
3 people
Team
150+ daily users across 6 roles
Users
450 - 2,000 engine parts produced weekly
Scale
10 months - hard deadline
Timeline
Situation
A central Enterprise Technology team informed the Additive Manufacturing (AM) department that they would be disabling or “sunsetting” the software tools that we used to manage the AM floor including machine setups, build tracking, traceability, powder testing results, Non-Destructive Testing (NDT) results, anomalies, machine onboarding, and more. In October of 2023, were told that this tool would be unavailable to us starting in July of 2024. This gave us 10 months to come up with a new solution.
TL;DR
Long Story Short…
Task
Identify or develop a new tool that can take over all of the function of our existing production floor management system, and ideally improve on known weaknesses in our process. The tool should be built for use by over 150 users across 6 different groups including machine operators, materials and process engineers, managers, design engineers (AM customers), post-processing teams, and AM engineers.
Action
Work in a team of 3 (myself, a software developer, and a machine programmer) to build a new system that is user-forward and meets all ITAR and quality requirements. I pitched solutions and worked to obtain approvals from the enterprise technology team in order to move forward. Ultimately, we needed to completely switch the operations team onto this new system by the sunset date of July so that there was no production downtime.
Result
The development and rollout was completed on time and with a successful rollout.There was zero production downtime due to duplicating data inputs while we tested out the new system and made improvements. The system now serves over 1000 users, and the head of IT at Blue Origin dubbed our solution “the perfect fit” for Blue’s needs according to a LinkedIn post.
Get ready to dive into…
The Long Story
PROJECT SUMMARY
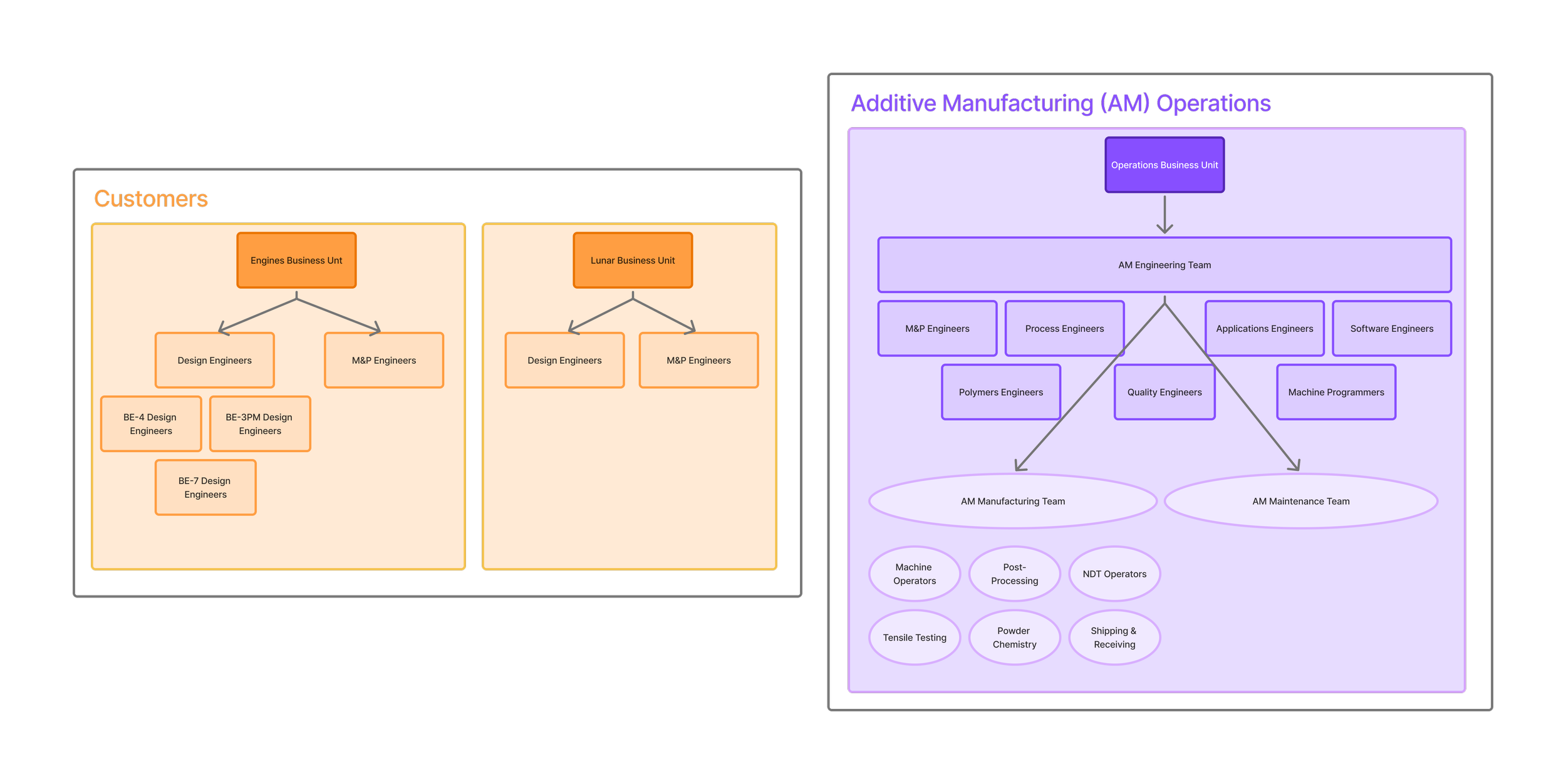
Team Structure
When a central Enterprise Technology team informed our additive manufacturing team that our production floor system would be sunset in 10 months, with no viable replacement offered, I volunteered to lead the effort. I took on the roles of designer, project manager, and product owner simultaneously, working alongside a machine programmer and a software engineer to build something from scratch that our team and roughly 150 users across six distinct teams could depend on.
What followed was ten months of navigating an approval process that consistently blocked our path forward, a mid-project pivot that required us to abandon our planned approach entirely, learn React, and rebuild, all while keeping the team aligned and the deadline in sight.
The system launched on time with no production downtime, and every rocket engine part continued to be tracked, traced, and accounted for throughout the transition.
01 THE STAKES
Existing system shutdown in 10 months
This system ran the entire additive manufacturing floor
Hard deadline, if the software wasn’t fully replaced in time, the floor couldn’t operate
ITAR compliance and quality traceability are primary requirements
An internal enterprise technology team informed our additive manufacturing team that upcoming system updates would create ITAR compliance issues, and they had decided to sunset the tool we used to run the additive manufacturing (AM) production floor.
This was the system that tracked machine setups, traced parts and powder through the build process, managed quality checklists, and logged anomalies. We had ten months to replace it with nowhere to start.
The stakes were straightforward: if we didn't have something new in place by the deadline, the floor would not be able to operate. Since AM parts go into every Blue Origin engine and rocket build, that meant delayed rocket launches.
The new system would need to be ITAR compliant (including no cloud-based data storage, very strict cyber security, and record-keeping longevity) and tracking quality requirements were necessary to be baked in from the beginning in order to maintain the same quality standards.
WHAT MADE THINGS MORE DIFFICULT
Any software we purchased or built had to be approved by the same Enterprise Technology team that was sunsetting our current tool.
They held authority over every decision, were difficult to get time with, and consistently rejected our proposed alternatives without offering anything in their place.
Without their sign-off, we couldn't move forward, and getting that sign-off took months of effort that never fully resolved the way we needed it to.
02 UNDERSTANDING THE SYSTEM BEFORE DESIGNING
I was a Process Engineer, so I understood the system, it’s strengths, quirks, workarounds, and weaknesses
I was a user for the system I was designing. I was close with all users, giving me a strong design foundation
① I defined requirements with users, not for them
I worked directly with end users across all six roles to identify what they needed most, what they hoped for in the future, and what the minimum viable product had to include.
I owned the requirements document and the roadmap throughout, and rather than routing design decisions through a formal approval process, I kept sign-off in the hands of the people who would actually be using the system every day.
This approach meant alignment was something we built in from the beginning rather than something we had to negotiate at the end.
One of the things that shaped my approach to this project most was that I wasn't coming into it as an outside designer. I was an AM Process Engineer who had worked on that floor, traced anomalies through the production pipeline, managed machine qualifications, and experienced firsthand what it felt like when data was missing or inconsistent downstream.
That context meant I understood the system I was designing for in a way that went beyond what any amount of user research could have given me — I had lived the same frustrations as the people I was designing for, and I understood what it actually cost when things went wrong.
② I mapped where the old system was failing
The most significant problem with the old system wasn't that it was missing features, it just offered too much flexibility. Every user could create their own custom views, add fields, and hide data they didn't want to see, which meant that over time each operator had quietly developed their own version of the process.
Engineers reviewing data downstream often had no way of knowing which variation had been followed, and parts with incomplete or inconsistent records had to be scrapped.
The quality standards on the floor were maintained throughout, but solving the data consistency problem meant we could stop losing parts that could have been saved with better information.
③ I identified which users had the most power and pain
Understanding the dynamics between user groups was one of the most important things I did early in the process.
Machine operators had significant power. They were entering data in real time, and an accidental override could corrupt a build record that engineers would rely on later.
Process and M&P engineers, on the other hand, carried the most pain. They were responsible for reviewing everything downstream, identifying anomalies like powder samples out of spec, tensile failures without traceable history, and troubleshooting issues that often had roots much earlier in the process.
This understanding directly shaped the design. I focused on constraining what operators could accidentally change while giving process engineers real tools to do their jobs more effectively.
ET initially directed us to use a simple spreadsheet tool, but what we needed was a relational database (a system where data could link across records and communicate in both directions). A spreadsheet fundamentally couldn't support that.
My team researched alternatives, identified Baserow + a low-code app builder as the right fit and presented a full requirements mapping to make our case.
ET approved Baserow, but blocked the low-code app builder we needed alongside it to handle custom logic and automations, citing budget concerns, even though I had mapped out the cost and the proposed solution cost significantly less than the system we were replacing.
When we asked for software engineers from their team to help fill the gap, they declined. When they redirected us to another internal team, that team was unresponsive. This pattern of surfacing a requirement, meet it, only to get blocked on something new repeated itself for months.
HOW I RESPONDED
1 - Build the business case formally
I worked with the machine programmer to map every one of our requirements against CT's approved tools and our proposed alternatives and presented them side by side, in plain language. When that wasn't enough, I wrote a formal business case and brought in the AM director to present to CT's management directly. Even that was ultimately unsuccessful, but it created a paper trail and made the stakes undeniable.
2 - Start building before everything was settled
If I waited until we got approvals to move forward, we wouldn’t have gotten anywhere at all. So, my team started building before final approvals were in place. This meant restarting twice. But each restart was faster than the last, we'd learned what really mattered, and having a working prototype in front of stakeholders was far more persuasive than any document.
3- Cut scope and learn to code
When the low-code tool was denied and ET offered no alternative solution, we had one software engineer with about 20% of his time available. Up to that point we had been building against a stack that included a low-code app builder, Supabase, Databricks, and custom API integrations to handle the relational backend. I had been deeply involved in this work with the software engineer, alongside the machine programmer. When that path was closed, we sat down and made a plan. We cut every “nice-to-have” feature, defined the bare minimum viable system, and pivoted to building directly in React within an existing internal web application. The machine programmer and I learned enough to contribute meaningfully to development, and I reorganized the project plan around what we could realistically ship.
4 - Design for change
Because approvals kept shifting what we could build, I designed features to be modular from the start and used feature flags so we could ship incrementally. I kept technical documentation current with every iteration. This was partially to speed up future approvals, and partially so the team always knew where we stood and what could be deprioritized if needed.
03 NAVIGATING AN APPROVAL MAZE
The most difficult part of this process was navigating an approval process that consistently moved the goalposts and offered no viable path forward.
Understanding how to keep making progress through that environment became just as important as any design decision I made.
WHAT HAPPENED IN THESE APPROVAL LOOPS?
04 DESIGNING FOR REAL PEOPLE IN REAL CONDITIONS
Designing for this environment required holding two very different contexts in mind at once. On the production floor, operators are moving between machines, wearing PPE, working with tablets in gloved hands in a loud environment. The old system had been designed for desktop with small buttons, multiple browser tabs, and with no consideration for how it would actually feel to use it in those conditions. At the same time, process and M&P engineers and managers were reviewing the same data on desktop computers, often looking across multiple records to identify patterns or anomalies. Every decision I made had to work for both.
01 - Glove friendly, mobile-first for operators
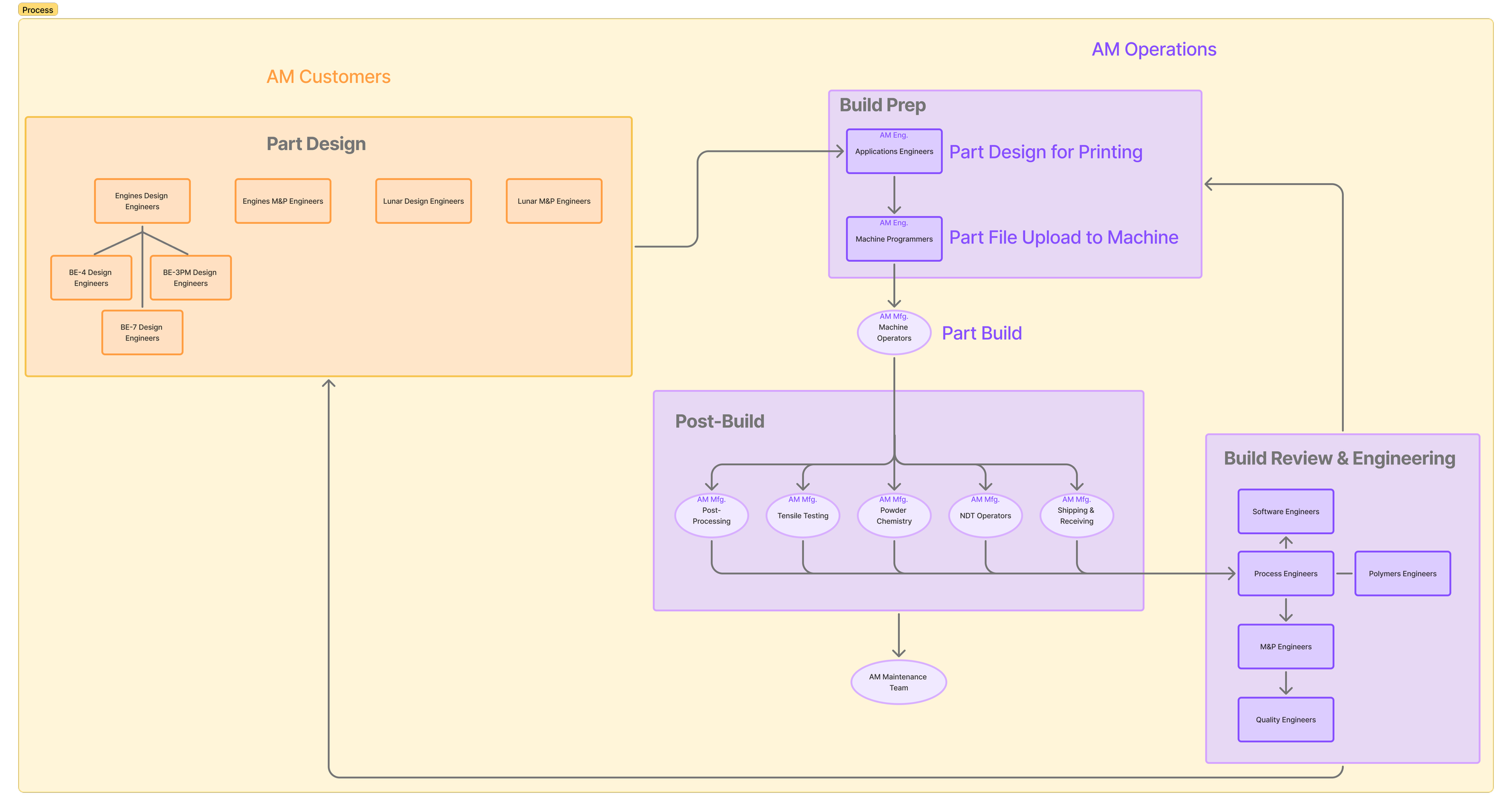
I focused on large touch targets, simplified data entry, clear task completion states, and auto-save so operators didn't have to worry about losing progress. The previous system required navigating multiple interfaces to complete a single machine setup task. The new design consolidated everything into one interaction per task. I also made sure the experience translated seamlessly between iPad and desktop so we weren't maintaining two separate systems.
02 - Standardized machine setup checklist
The machine setup checklist was the part of the old system where things went wrong most often, and the reason was the flexibility the old system afforded. Because every user could build their own custom view, operators had each quietly developed their own version of the checklist over time. This resulted in different fields, different order, and different steps included or excluded. Engineers reviewing the results downstream often had no way of knowing which version had been followed, and data was often missing or incorrect. The new checklist was standardized and locked for everyone: same fields, same order, same process, every time. That consistency wasn't a design preference, it was a quality requirement, and it was one of the most important decisions I made on this project.
03 - Giving process engineers structure, not just visibility
Process engineers were responsible for identifying and resolving anomalies that often showed up long after the original issue occurred — missing powder sample data, NDT gaps, tensile failures without traceable context. They had visibility into a lot of information, but no structured way to flag problems and move them toward resolution. I designed a continuous improvement intake where anyone on the team could submit an issue alongside a proposed fix, and I led triage sessions with managers to delegate ownership of each item. It gave engineers a clear path from problem to resolution rather than leaving them as the informal catch-all for everything that went wrong.
04 - Protecting the team from too many good ideas
Something I hadn't anticipated going into this project was how much energy I would spend managing enthusiasm rather than resistance. Users had been frustrated with the old system for a long time, and once they understood what we were building, they were genuinely excited to contribute. Ideas came in constantly. After every major constraint change forced us to redefine scope, I ran prioritization sessions with users to re-anchor the team to MVP and make sure the features we were building were the ones that mattered most. Learning to say "not right now, and here's why" was one of the more important skills I developed on this project.
My title throughout this project was Process Engineer II. I wasn't formally the project manager, the product owner, or the design lead. I stepped into all three of those roles because the work needed someone, and I was the person on the team who understood both the production system and the people who depended on it. What I've learned is that leading without a formal title means you earn trust through the quality of your decisions and your ability to give people clarity when things are uncertain, which is something I've always valued and tried to practice.
With the team, that meant being the person who named the situation clearly when things were unclear and made a decision so we could keep moving. When ET blocked a path forward, I brought the team together, acknowledged what had changed, and redirected our energy rather than letting frustration sit. When scope had to be cut (which was more often than anticipated), I ran that conversation with users directly so the decisions felt collaborative rather than imposed. People were understandably frustrated with the pivots, but they remained genuinely invested in the project,.
With stakeholders above the team, I learned quickly that presenting technical requirements wasn't enough on its own. I brought in the AM director. I escalated toward ET's management. I translated the technical constraints into business risk and put it in writing so the stakes were undeniable. It didn't resolve the approval situation the way I had hoped, but it kept us moving and ensured that every obstacle we encountered was clearly documented.
HOW THE TEAM WORKED
The machine programmer was fully dedicated to the project. I was splitting my time about 50/50 with other engineering responsibilities, and our software engineer had roughly 20% of his time available. We were a small team working with limited bandwidth, and everyone understood what was on the line.
Because users had been involved throughout the entire design process, by the time we were approaching launch they weren't learning something unfamiliar — they were seeing their own ideas and feedback reflected back in a working system. Resistance was minimal. The harder challenge, honestly, was keeping scope contained when people were excited to contribute more than the timeline could support.
05 LEADING WITHOUT A TITLE FOR IT
06 TIMELINE
Months 1–3: Discovery, requirements, and approvals
User research across 6 roles.
Requirements documented and mapped.
First software proposals submitted and rejected.
Business case built, and approvals loops began.
Prototyping started in parallel.
Months 4–6: Low-code tool rejected. Pivot to custom build.
Baserow approved; low-code app builder denied.
ET declined to provide engineering support.
Team convened, scope cut to bare MVP in collaboration with users.
Project management reorganized to reflect new reality.
Machine programmer and I began learning enough to contribute to development alongside the software engineer.
Months 7–9: Build, test, and iterate
Modular feature development with feature flags.
End user testing sessions.
Both old and new systems running in parallel (for redundancy so that we still had room to fix, add, and remove features).
Continuous documentation for IT submissions.
March 2024: Pilot rollout
Controlled launch with dedicated training sessions by user group.
Refinement period built in before full rollout.
Users were already familiar since they'd been part of building it since the beginning.
April 2024: Full rollout, with both systems remaining active
Old and new systems running simultaneously.
Data reported to both for full redundancy.
Zero production downtime.
July 2024: Old system sunset
Full transition complete.
ITAR-compliant.
On schedule.
07 RESULTS
Outcomes at Launch
Zero production downtime
150 users onboarded across 6 roles
ITAR compliant from day one
Standardized QA checklists
Reduced manual entry errors
One Year Later
Improved anomaly traceability
Delivered on time
Enterprise Technology had approved Baserow only as a partial component of a larger stack, not as the central hub we had envisioned and argued for. One year after the system launched, Baserow's founder posted publicly about the company's adoption of the platform at Blue. The same platform our team had spent months making the case for, documenting requirements around, and ultimately building on despite significant resistance.
“Nearly 1,000 people across the Engines, Lunar, and Alloy teams now collaborate on Baserow. Production data moved out of scattered spreadsheets into a single real-time hub. Customers have full visibility into production order status. All manufacturing sites share real-time data, with secure on-premise and air-gapped deployments.”
The platform our three-person team evaluated, advocated for, and built on through months of rejections, requirements mapping, and formal escalations, became the company's central hub for manufacturing data at scale. The requirements document we put in front of ET wasn't wrong. It just took a year for the outcome to prove it.
The React-based interface tool we developed in tandem with Baserow is still in use today, and is continuing to be built upon to include all of our “nice-to-have” features we had to delay in order to build the minimum viable product on time.
08 REFLECTION
I left the company before the system went live, as part of a company-wide reduction in February. The project shipped on time with no production downtime, and my manager's reflection afterward stayed with me: "The reason it succeeded on rollout was because of the way she set up the project and the team for success." I think about that a lot, because the outcome really wasn't determined at launch, it was determined months earlier, in how requirements were defined, how the team was structured around a shifting set of constraints, and how consistently users were treated as collaborators rather than recipients of something being built for them.
If I could go back, the thing I would do differently is treat organizational resistance as a design constraint from the very beginning. I spent months trying to resolve the ET situation through escalation and documentation, which was the right approach, but I didn't build it into the project plan the way I would now. The time those approval loops cost us was time we couldn't recover, and I would have mapped the stakeholder landscape with the same rigor I applied to user flows.
What I would do again without hesitation: start building before everything is approved. I would also involve users throughout the entire process again, because by the time we reached launch, they weren't onboarding to something unfamiliar. They were seeing their own ideas come back to them in a working system, and that made all the difference.